
It is going to get weird before it becomes normal
Things are about to get a whole lot spookier in the world of bits in the upcoming months. For all practical purposes AGI is here at least for the laptop class - but that doesn’t mean everyone can go back to pursuing their passions and UBI can become commonplace. We are still some time away from the metaphorical societal collapse but I want this article to be the canary in the coal mine - think of it as a dispatch from December 2019 from Wuhan before the world changed forever.
If you have been following the world of general purpose agents which originally started as coding agents but then bitter lesson, as always, has the last laugh and transmogrified coding first agents to terminal based computer use agents (what is a modern day computer if not a terminal with a snazzy GUI) - people are building RTS games, Cursor built a browser from scratch*. METR's long horizon task completion graph is telling in the step change in model capability to autonomously reason->tool-call->reason (interleaved thinking) their way to solving a task. The newer frontier models are “natively agentic” which means they are not just next best token predictor but next best action token generators as well giving the brain digital arms and legs.
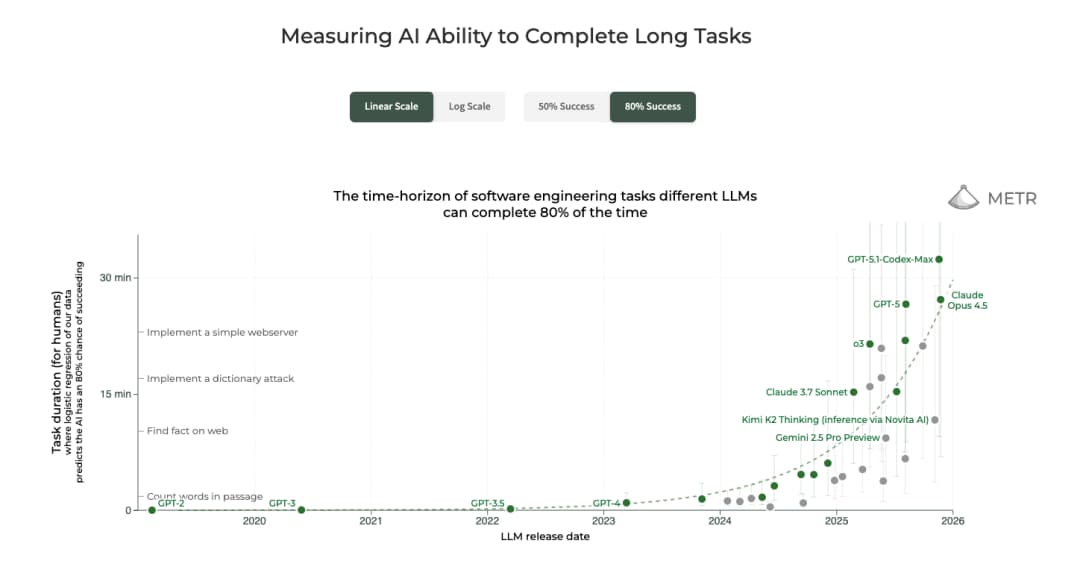
And this has been achieved with models that have been pre-trained on Blackwell and Hopper architecture GPUs along with TPUs with a context window of 200k (Opus 4.5) to 1-2M (Grok 4.1 and Gemini 3 family of models). So why would the next couple of months get weirder you ask? Well it is a combination of two things rooted in infra.
1) Gigawatt scale DCs go online in 2026
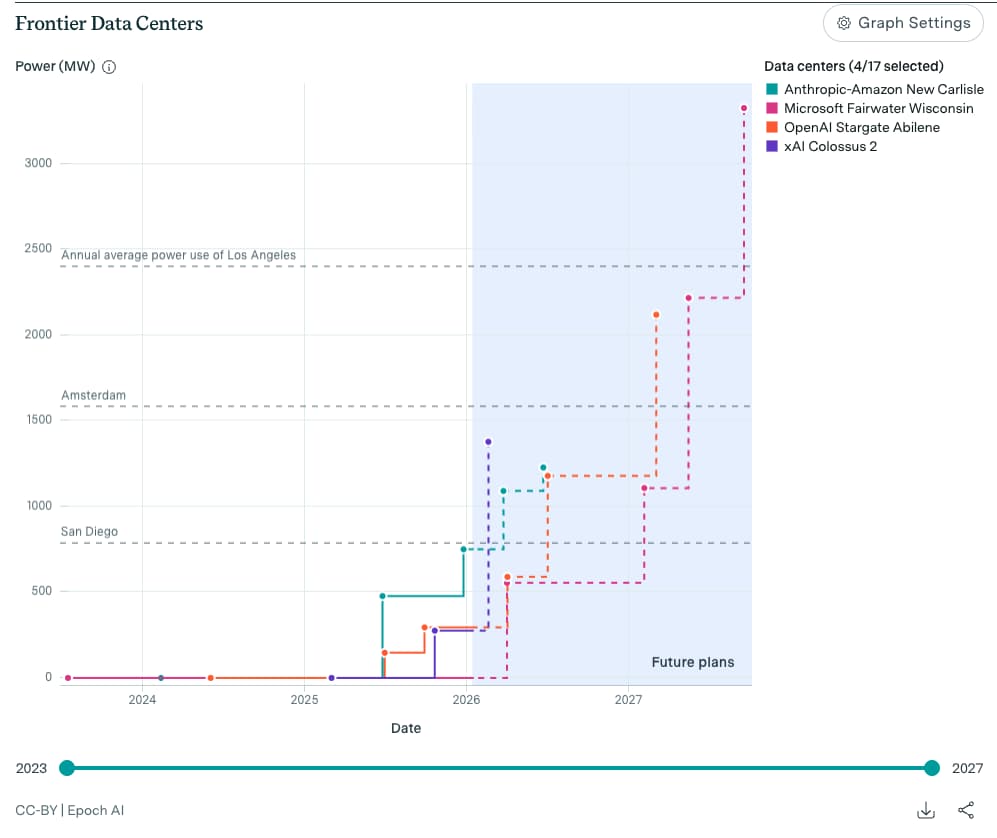
More powerful data centres will start to go online in the middle of this year (OpenAI’s Stargate-Abeline and Anthropic-AWS Gigawatt ) which means more beefier and capable models would have started their hero pre-training runs and current models will also become smarter via post-training. Opus 4.7 theoretically could come with a default 1M context window which means reduced compaction frequency hence long range tasks can be done in a single session/“it oneshotted it bro" without having to conserve for the context window. We can see by the end of the year 1M context windows becoming default for most frontier models to accomodate for increased reasoning tokens thanks to test-time scaling to solve long horizon tasks.
2) Vera Rubin goes live mid 2026
NVIDIA’s latest and greatest AI token factory chip will go into production and will be seen across the various gigawatt scale data centres mentioned in the above Epoch AI graph. While Vera Rubin has the usual performance jumps you would expect from an annual release cycle of super chips, this generation was unique considering it has fundamentally decoupled the two major parts of inference: prefill and decode finally enabling disaggregated inference.
While Rubin does not increase a model’s advertised context window, but it can materially increase the the conversation history an agent can keep active without quality-degrading compaction, because KV cache becomes a first-class, shareable memory tier via ICMS (pic below). That shows up as faster multi-turn sessions, fewer reprefills, and lower tail latency at long context. This will allow for faster retreival of "conversational session context” in turn boosting performance of muti-turn/hop agentic reasoning; What does this mean? Next time your claude code/codex compacts a conversation the performance degradation will not be as bad as it is now!

Parting Thoughts
We are still early in the takeoff phase. Coding agents will be the base substrate on which "mythical AGI" will be built (if you still think it isn. It was very prescient of Anthropic to devote all their resources and focus on solving “coding” which led to broader terminal based computer use becoming better. For software-first teams, engineers have always been the primary source of leverage. Coding agents provide baseline capability on their own, but their real value is multiplicative. Pair them with engineers who can effectively direct them and the returns become exponential: a capable engineer's 10x output becomes 100x. The distribution of engineering productivity is about to become far more skewed. More frequent OTA updates (as evidenced by how quickly the claude code team is shipping updates and new features). We are in uncharted territories where the tool that was used to make the tool is generally available for everyone to build (hopefully not just more tools) in real-time.
I believe Opus 4.5 was a watershed moment in natively agentic models not because it was a great coding model (GPT 5.2 codex is honestly better for long horizon refactoring tasks IMO) but it showed us how scaling and pre-training was not dead and RL based post-training on model+harness combo can yield step jump in performance. What this also means is every new model drop in 2026 will not make you catch your breath - the progress would seem incremental but compounding.
While there will always be skeptics who will constantly shift goalposts as to what AGI is and what coding agents cannot do - that is often myopic reasoning completely oblivious of larger forces in play in the very near future.
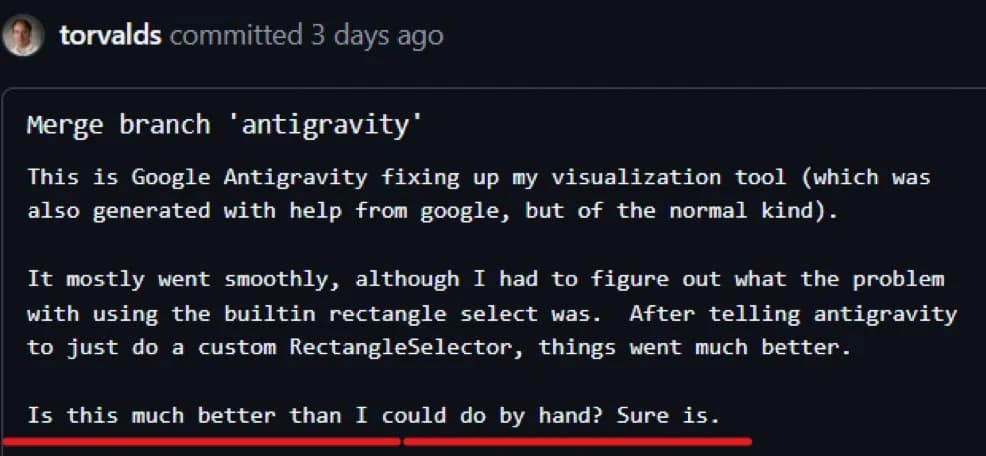
P.S. Linus Torvaldis (inventor of Git and Linux) has started vibe coding on Antigravity. Show this to your ever skeptical 'Senior Software Engineer' friend who is yet to wake up to the surprising effectiveness of these computer use coding agents (ifykyk).
P.P.S - this article was entirely written and edited on my custom markdown WYSIWYG editor that I vibe-coded with the help of Codex and CC!